Kiwix#
With Kiwix it is possible to have a copy of Wikipedia and of other websites and read them offline.
Vedi anche
Kiwix lets you access free knowledge – even offline [1]
A collection of scripts I have written and/or adapted that I currently use on my systems as automated tasks [2]
Base directory for downloading zim files [3]
Download large file in python with requests - Stack Overflow [4]
python - Performant replacement for IPython !shell-command magic - Stack Overflow [5]
shutil — High-level file operations — Python 3.10.3 documentation [6]
Setup#
install the dependencies
apt-get install python3-requests python3-bs4 python3-yaml aria2 kiwix-tools kiwixinstall fpyutils. See reference
create a new user
useradd --system -s /bin/bash -U kiwix passwd kiwix usermod -aG jobs kiwix
create the jobs directories. See reference
mkdir -p /home/jobs/{scripts,services}/by-user/kiwixcreate the
script/home/jobs/scripts/by-user/kiwix/kiwix_manage.py#1#!/usr/bin/env python3 2# 3# kiwix_manage.py 4# 5# Copyright (C) 2020-2022 Franco Masotti (franco \D\o\T masotti {-A-T-} tutanota \D\o\T com) 6# 7# This program is free software: you can redistribute it and/or modify 8# it under the terms of the GNU General Public License as published by 9# the Free Software Foundation, either version 3 of the License, or 10# (at your option) any later version. 11# 12# This program is distributed in the hope that it will be useful, 13# but WITHOUT ANY WARRANTY; without even the implied warranty of 14# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the 15# GNU General Public License for more details. 16# 17# You should have received a copy of the GNU General Public License 18# along with this program. If not, see <http://www.gnu.org/licenses/>. 19"""kiwix_manage.py.""" 20 21######## 22# Main # 23######## 24 25import datetime 26import pathlib 27import re 28import shlex 29import shutil 30import subprocess 31import sys 32import urllib.parse 33 34import bs4 35import fpyutils 36import requests 37import yaml 38 39 40def separate_pattern_from_string(string: str, pattern: str) -> tuple: 41 r"""Separate a pattern from a string.""" 42 string_without_pattern = remove_component(string, pattern) 43 component = find_component(string, pattern) 44 45 return string_without_pattern, component 46 47 48def separate_pattern_from_strings(strings: list, pattern: str) -> dict: 49 r"""Separate a batch of strings from their patterns.""" 50 for string in strings: 51 if not isinstance(string, str): 52 raise TypeError 53 54 elements = dict() 55 # Populate the date elements. 56 for string in strings: 57 common, component = separate_pattern_from_string(string, pattern) 58 if common not in elements: 59 # Build an empty list of length corresponding 60 # to the number of entries without the date component in the file name. 61 elements[common] = list() 62 elements[common].append(component) 63 64 return elements 65 66 67def filter_max_elements_in_dict_nested_lists(elements: dict) -> dict: 68 r"""Given a dictionary with lists, find the maxium elements of each list and remove the other elements.""" 69 # Get the most recent dates by group and rebuild the URLs. 70 filtered_elements = dict() 71 for element in elements: 72 filtered_elements[element] = max(elements[element]) 73 74 return filtered_elements 75 76 77def get_most_recent_elements(uris: list, date_regex_pattern: str, 78 date_format_string: str) -> dict: 79 r"""Filter elements by date and return the most recent ones.""" 80 for uri in uris: 81 if not isinstance(uri, str): 82 raise TypeError 83 84 elements = separate_pattern_from_strings(uris, date_regex_pattern) 85 # Transform the date strings to datetime objects. 86 for element in elements: 87 i = 0 88 while i < len(elements[element]): 89 elements[element][i] = str_to_datetime(elements[element][i], 90 date_format_string) 91 i += 1 92 return filter_max_elements_in_dict_nested_lists(elements) 93 94 95def filter_uris_by_pattern(uris: list, pattern: str): 96 r"""Filter URIs by regex pattern.""" 97 filtered_uris = list() 98 for uri in uris: 99 if find_component(uri, pattern) is not None: 100 filtered_uris.append(uri) 101 102 return filtered_uris 103 104 105def compare_uris(local_uris: dict, remote_uris: dict) -> tuple: 106 r"""Given two sets of URIs select the actions to do with the elements each one by placing them into two new sets.""" 107 files_to_download = list() 108 files_to_delete = list() 109 for remote in remote_uris: 110 exists_locally = False 111 for local in local_uris: 112 if remote == local: 113 exists_locally = True 114 # Get the element in the local files list corresponding to the current remote file. 115 # Only download fresh files. 116 if local_uris[local] < remote_uris[remote]: 117 files_to_download.append( 118 rebuild_uri_with_date(remote, remote_uris[remote], 119 '%Y-%m')) 120 files_to_delete.append( 121 rebuild_uri_with_date(local, local_uris[local], 122 '%Y-%m')) 123 if not exists_locally: 124 files_to_download.append( 125 rebuild_uri_with_date(remote, remote_uris[remote], '%Y-%m')) 126 127 return files_to_download, files_to_delete 128 129 130def download_files(files_to_download: list, downloader: str, 131 downloader_args: str, root_url: str, file_directory: str): 132 r"""Download a batch of files.""" 133 delete_temporary_directory = False 134 for i, download in enumerate(files_to_download): 135 full_remote_uri = rebuild_uri(root_url, download) 136 full_local_uri = rebuild_uri(file_directory, download) 137 if i == len(files_to_download) - 1: 138 delete_temporary_directory = True 139 download_binary_file(full_remote_uri, full_local_uri, downloader, 140 downloader_args, 0o700, 141 delete_temporary_directory) 142 143 144def delete_files(files_to_delete: list, file_directory: str): 145 r"""Delete a batch of files.""" 146 for delete in files_to_delete: 147 full_local_uri = rebuild_uri(file_directory, delete) 148 delete_file(full_local_uri) 149 150 151######### 152# Utils # 153######### 154 155 156def get_relative_path(path: str) -> str: 157 r"""Get the last component of a path.""" 158 return str(pathlib.Path(path).name) 159 160 161def get_relative_paths(paths: list) -> list: 162 r"""Get the last components of a list of paths.""" 163 relative = list() 164 for path in paths: 165 relative.append(get_relative_path(path)) 166 167 return relative 168 169 170def get_last_path_component_from_url(url: str) -> str: 171 r"""Transform a string to a datetime object.""" 172 component = urllib.parse.urlsplit(url).path 173 return get_relative_path(component) 174 175 176def remove_component(element: str, pattern: str) -> str: 177 r"""Remove the date component from the name.""" 178 return re.split(pattern, element)[0] 179 180 181def find_component(element: str, pattern: str) -> str: 182 r"""Return the date component from the name.""" 183 f = re.findall(pattern, element) 184 if len(f) == 1: 185 return f[0] 186 else: 187 return None 188 189 190def str_to_datetime(date: str, 191 date_formatting_string: str) -> datetime.datetime: 192 r"""Transform a string into a datetime object.""" 193 return datetime.datetime.strptime(date, date_formatting_string) 194 195 196def datetime_to_str(date: datetime.datetime, 197 date_formatting_string: str) -> str: 198 r"""Transform a datetime object into a string.""" 199 return datetime.datetime.strftime(date, date_formatting_string) 200 201 202def rebuild_uri(uri_base: str, path: str) -> str: 203 """Rebuild a URI by a trailing forward slash if necessary and a path. 204 205 ..note: see https://stackoverflow.com/a/59818095 206 """ 207 uri_base = uri_base if uri_base.endswith('/') else f'{uri_base}/' 208 return uri_base + path 209 210 211def rebuild_uri_with_date(uri_base: str, 212 date: datetime, 213 date_formatting_string: str, 214 extension: str = '.zim') -> str: 215 r"""Rebuild the original URI which has been stripped from the date and file extension components.""" 216 return uri_base + datetime_to_str(date, date_formatting_string) + extension 217 218 219def get_a_href_elements_from_url(url: str) -> list: 220 r"""Given a url, download the file and, if it is an HTML file, find all "a href" elements.""" 221 soup = bs4.BeautifulSoup(requests.get(url, timeout=60).text, 'html.parser') 222 # Get the content of the HTML tag. 223 return [link.get('href') for link in soup.find_all('a')] 224 225 226def download_binary_file_requests(url: str, destination: str): 227 r"""Download a binary file with Python Requests.""" 228 # See https://stackoverflow.com/questions/16694907/download-large-file-in-python-with-requests/39217788#39217788 229 # 230 # Copyright (C) 2016 John Zwinck @ Stack Exchange (https://stackoverflow.com/questions/16694907/download-large-file-in-python-with-requests/39217788#39217788) 231 # Copyright (C) 2020 Martijn Pieters @ Stack Exchange (https://stackoverflow.com/questions/16694907/download-large-file-in-python-with-requests/39217788#39217788) 232 # Copyright (C) 2020 Franco Masotti (franco \D\o\T masotti {-A-T-} tutanota \D\o\T com) 233 # 234 # This script is licensed under a 235 # Creative Commons Attribution-ShareAlike 4.0 International License. 236 # 237 # You should have received a copy of the license along with this 238 # work. If not, see <http://creativecommons.org/licenses/by-sa/4.0/>. 239 240 with requests.get(url, stream=True, timeout=60) as r: 241 with open(destination, 'wb') as f: 242 shutil.copyfileobj(r.raw, f) 243 244 245def download_binary_file_aria2c(downloader_args: str, 246 parent_directory: str, 247 url: str, 248 destination: str, 249 temporary_directory: str = 'tmp', 250 delete_temporary_directory: bool = False): 251 r"""Download a binary file with aria2.""" 252 p = shlex.quote(parent_directory) 253 d = shlex.quote(destination) 254 u = shlex.quote(url) 255 # Get the relative path. 256 t = str(pathlib.Path(shlex.quote(temporary_directory)).name) 257 pt = str(pathlib.Path(p, t)) 258 ptd = str(pathlib.Path(pt, d)) 259 260 # Save the file to a temporary file so that if the download is interrupted 261 # the pipeline does not detect that the file exists. 262 command = 'aria2c ' + downloader_args + ' --dir=' + pt + ' --out=' + d + ' ' + u 263 try: 264 return_code = fpyutils.shell.execute_command_live_output(command) 265 if return_code == 0: 266 try: 267 shutil.move(ptd, p) 268 if delete_temporary_directory: 269 try: 270 # See https://docs.python.org/3/library/shutil.html?highlight=shutil#shutil.rmtree.avoids_symlink_attacks 271 if shutil.rmtree.avoids_symlink_attacks: 272 shutil.rmtree(pt) 273 else: 274 raise shutil.Error 275 except shutil.Error as e: 276 print(e) 277 except shutil.Error as e: 278 print(e) 279 else: 280 sys.exit(1) 281 except subprocess.SubprocessError as e: 282 print(e) 283 raise e 284 sys.exit(1) 285 286 287def get_parent_directory_name(path: str) -> str: 288 r"""Get parent directory name.""" 289 return str(pathlib.Path(path).parent) 290 291 292def pre_download_hooks(destination: str, permissions: int = 0o700): 293 r"""Run selected actions before downloading the files.""" 294 pathlib.Path(destination).parent.mkdir(mode=permissions, 295 parents=True, 296 exist_ok=True) 297 298 299def post_download_hooks(path: str, permissions: str): 300 r"""Run selected actions after downloading the files.""" 301 # Change file permissions. 302 pathlib.Path(path).chmod(permissions) 303 304 305def download_binary_file(url: str, 306 destination: str, 307 downloader: str = 'requests', 308 downloader_args: str = '', 309 permissions: int = 0o700, 310 delete_temporary_directory: bool = False): 311 r"""Download a binary file.""" 312 if downloader not in ['requests', 'aria2c']: 313 raise ValueError 314 315 print('Downloading ' + url + ' as ' + destination) 316 pre_download_hooks(destination, permissions) 317 if downloader == 'requests': 318 download_binary_file_requests(url, destination) 319 elif downloader == 'aria2c': 320 download_binary_file_aria2c(downloader_args, 321 get_parent_directory_name(destination), 322 url, get_relative_path(destination), 'tmp', 323 delete_temporary_directory) 324 post_download_hooks(destination, permissions) 325 326 327def delete_file(file: str): 328 r"""Delete a file.""" 329 print('Deleting ' + file) 330 pathlib.Path(file).unlink() 331 332 333def list_directory_files(directory: str) -> list: 334 r"""Get a list of files in a directory.""" 335 files = list() 336 p = pathlib.Path(directory) 337 if p.is_dir(): 338 for child in p.iterdir(): 339 if child.is_file(): 340 files.append(str(child)) 341 342 return files 343 344 345def run_kiwix_server(url_root_location: str, threads: int, port: int, 346 directory: str, options: list): 347 r"""Serve the ZIM files.""" 348 opts = '' 349 for o in options: 350 opts += ' ' + shlex.quote(o) 351 352 command = 'kiwix-serve --urlRootLocation ' + shlex.quote( 353 url_root_location) + ' --threads ' + shlex.quote( 354 str(threads)) + ' --port ' + shlex.quote(str( 355 port)) + ' ' + opts + ' ' + shlex.quote(directory) + '/*.zim' 356 fpyutils.shell.execute_command_live_output(command) 357 358 359def pipeline(): 360 r"""Run the pipeline.""" 361 # Load the configuration. 362 configuration_file = shlex.quote(sys.argv[1]) 363 action = shlex.quote(sys.argv[2]) 364 config = yaml.load(open(configuration_file), Loader=yaml.SafeLoader) 365 serve = config['serve'] 366 downloads = config['downloads'] 367 if 'options' in serve: 368 options = serve['options'] 369 else: 370 options = list() 371 372 if action == '--serve': 373 run_kiwix_server(serve['url root location'], serve['threads'], 374 serve['port'], serve['directory'], options) 375 elif action == '--download': 376 for section in downloads: 377 root_url = rebuild_uri(downloads[section]['root url'], '') 378 379 remote_uris = get_a_href_elements_from_url(root_url) 380 remote_uris = filter_uris_by_pattern( 381 remote_uris, 382 downloads[section]['regex patterns']['files to download']) 383 remote_uris = filter_uris_by_pattern( 384 remote_uris, downloads[section]['regex patterns']['date']) 385 remote_uris = get_relative_paths(remote_uris) 386 387 most_recent_remote_uris = get_most_recent_elements( 388 remote_uris, downloads[section]['regex patterns']['date'], 389 downloads[section]['date transformation string']) 390 391 local_uris = list_directory_files( 392 downloads[section]['download directory']) 393 local_uris = filter_uris_by_pattern( 394 local_uris, downloads[section]['regex patterns']['date']) 395 local_uris = get_relative_paths(local_uris) 396 397 most_recent_local_uris = get_most_recent_elements( 398 local_uris, downloads[section]['regex patterns']['date'], 399 downloads[section]['date transformation string']) 400 401 files_to_download, files_to_delete = compare_uris( 402 most_recent_local_uris, most_recent_remote_uris) 403 404 download_files(files_to_download, 405 downloads[section]['downloader']['name'], 406 downloads[section]['downloader']['args'], root_url, 407 downloads[section]['download directory']) 408 delete_files(files_to_delete, 409 downloads[section]['download directory']) 410 411 412if __name__ == '__main__': 413 pipeline()
create a
configuration file/home/jobs/scripts/by-user/kiwix/kiwix_manage.yaml#1# 2# kiwix_manage.yaml 3# 4# Copyright (C) 2020-2022 Franco Masotti (franco \D\o\T masotti {-A-T-} tutanota \D\o\T com) 5# 6# This program is free software: you can redistribute it and/or modify 7# it under the terms of the GNU General Public License as published by 8# the Free Software Foundation, either version 3 of the License, or 9# (at your option) any later version. 10# 11# This program is distributed in the hope that it will be useful, 12# but WITHOUT ANY WARRANTY; without even the implied warranty of 13# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the 14# GNU General Public License for more details. 15# 16# You should have received a copy of the GNU General Public License 17# along with this program. If not, see <http://www.gnu.org/licenses/>. 18 19serve: 20 threads: 24 21 port: 8888 22 directory: '/data/WEBSERVER/kiwix' 23 url root location: '/kiwix' 24 25 # A list of raw options for kiwix-serve. 26 # See 27 # kiwix-serve --help 28 options: [] 29 # - '--verbose' 30 31downloads: 32 wikipedia en: 33 root url: 'https://download.kiwix.org/zim/wikipedia' 34 regex patterns: 35 files to download: '^(wikipedia_en_physics_mini|wikipedia_en_computer_maxi|wikipedia_en_history_maxi|wikipedia_en_mathematics_maxi|wikipedia_en_medicine_maxi)' 36 date: '\d\d\d\d-\d\d' 37 date transformation string: '%Y-%m' 38 download directory: '/data/WEBSERVER/kiwix' 39 downloader: 40 # Supported downloaders: {aria2c,requests} 41 name: 'aria2c' 42 args: '--continue=true --max-concurrent-downloads=3 --max-connection-per-server=3 --split=3 --min-split-size=1M --max-overall-download-limit=256K' 43 wiversity en: 44 root url: 'https://download.kiwix.org/zim/wikiversity/' 45 regex patterns: 46 files to download: '^(wikiversity_en_all_maxi)' 47 date: '\d\d\d\d-\d\d' 48 date transformation string: '%Y-%m' 49 download directory: '/data/WEBSERVER/kiwix' 50 downloader: 51 name: 'aria2c' 52 args: '--continue=true --max-concurrent-downloads=3 --max-connection-per-server=3 --split=3 --min-split-size=1M --max-overall-download-limit=256K'
create the data directory which must be accessible by the
kiwixusermkdir /data/WEBSERVER/kiwix chmod 700 /data/WEBSERVER/kiwix chown kiwix:kiwix /data/WEBSERVER/kiwix
use this
Systemd service fileto serve the content/home/jobs/services/by-user/kiwix/kiwix-manage.serve.service#1# 2# kiwix-manage.serve.service 3# 4# Copyright (C) 2020,2022 Franco Masotti (franco \D\o\T masotti {-A-T-} tutanota \D\o\T com) 5# 6# This program is free software: you can redistribute it and/or modify 7# it under the terms of the GNU General Public License as published by 8# the Free Software Foundation, either version 3 of the License, or 9# (at your option) any later version. 10# 11# This program is distributed in the hope that it will be useful, 12# but WITHOUT ANY WARRANTY; without even the implied warranty of 13# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the 14# GNU General Public License for more details. 15# 16# You should have received a copy of the GNU General Public License 17# along with this program. If not, see <http://www.gnu.org/licenses/>. 18 19[Unit] 20Description=Serve kiwix files 21Wants=network.target 22After=network.target 23 24[Service] 25Type=simple 26ExecStart=/home/jobs/scripts/by-user/kiwix/kiwix_manage.py /home/jobs/scripts/by-user/kiwix/kiwix_manage.yaml --serve 27User=kiwix 28Group=kiwix 29Restart=always 30 31[Install] 32WantedBy=multi-user.target
use this
Systemd service fileto download the content/home/jobs/services/by-user/kiwix/kiwix-manage.download.service#1# 2# kiwix-manage.download.service 3# 4# Copyright (C) 2020 Franco Masotti (franco \D\o\T masotti {-A-T-} tutanota \D\o\T com) 5# 6# This program is free software: you can redistribute it and/or modify 7# it under the terms of the GNU General Public License as published by 8# the Free Software Foundation, either version 3 of the License, or 9# (at your option) any later version. 10# 11# This program is distributed in the hope that it will be useful, 12# but WITHOUT ANY WARRANTY; without even the implied warranty of 13# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the 14# GNU General Public License for more details. 15# 16# You should have received a copy of the GNU General Public License 17# along with this program. If not, see <http://www.gnu.org/licenses/>. 18 19[Unit] 20Description=Download kiwix files 21Wants=network-online.target 22After=network-online.target 23 24[Service] 25Type=simple 26ExecStart=/home/jobs/scripts/by-user/kiwix/kiwix_manage.py /home/jobs/scripts/by-user/kiwix/kiwix_manage.yaml --download 27User=kiwix 28Group=kiwix 29 30[Install] 31WantedBy=multi-user.target
fix the permissions
chown -R kiwix:kiwix /home/jobs/{scripts,services}/by-user/kiwix chmod 700 -R /home/jobs/{scripts,services}/by-user/kiwix
Download#
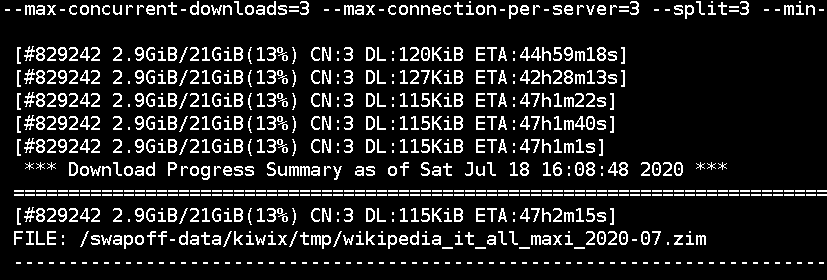
Download status of a zim file#
run the deploy script
start downloading the files
systemctl start kiwix-manage.download.servicewait for the files to be downloaded before going to the serve section
Serve#
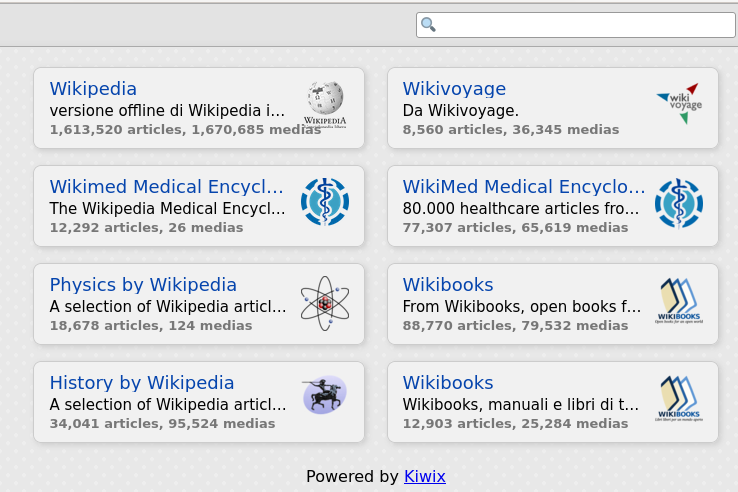
Example of served files by Kiwix#
run the deploy script
modify the reverse proxy port of your webserver configuration with
8888
Importante
After downloading new files you must rerun this service
Footnotes